Share this on:
What You'll Learn
Databricks has introduced liquid clustering, which is an innovative approach to organise data in Databricks. It replaces traditional optimization techniques like Z-Ordering and partitioning and overcomes their limitations. With the help of liquid clustering, organisations can optimize query performance and cost to run queries.
In this blog, we will delve into Databricks liquid clustering, its advantages, implementation, and real-world impact.
How is Data Organized in Databricks?
Before diving into liquid clustering, let’s understand the ways in which data is organized in Databricks.
1. Partitioning: The First Level of Organization
Partitioning has been the foundation of organizing data in data warehouses and data lake alike. It involves:
- Queries that require frequent filters and provides simple and effective way of organizing data.
- It divides data physically based on specific columns (ex: date, region)
- Also, while query execution, it helps in partition pruning that skips irrelevant data files.
However, it has a few limitations. For example: Too many partitions on data files could lead to small file problem which affects the performance of queries drastically. Also partitioning is only effective for queries that filter based on partition columns.
2. Z-Ordering
Z-Ordering is a technique that involves collocating related information of data in same set of files. It is said to be a better approach than partitioning.
The colocation is automatically leveraged by delta tables in delta lake that, in turn, leverage data skipping algorithms to drastically reduce the amount of data that needs to be read.
Although it is a good technique, it comes with its own limitations like:
- We can specify multiple columns for Z-ORDER BY, but its effectiveness decreases as you add more columns.
- Also, we need the statistics collected on Z-ORDER BY columns or else data pruning/skipping is avoided.
3. Liquid Clustering: Latest Feature
Liquid Clustering and Automatic liquid clustering are the latest advancements from Databricks which overcome the limitations of traditional approaches mentioned above.
Note: Databricks recommends using Databricks Runtime 15.2 and above for all tables that are liquid clustering enabled.
Liquid clustering allows you to redefine clustering keys without rewriting existing data. It can be beneficial for below use cases:
- Tables often filtered by high cardinality columns.
- Tables with significant skew in data distribution.
- Tables that grow quickly and require maintenance and tuning effort.
- Tables with concurrent write requirements.
- Tables with access patterns that change over time.
- Tables where a typical partition key could leave the table with too many or too few partitions.
To enable liquid clustering, we need to add CLUSTER BY command during table creation.
How LumenData Implemented Databricks Liquid Clustering for a FinTech client: Use Case
Recently, Lumendata had an opportunity to implement Databricks liquid clustering for one of our FinTech clients. This feature significantly helped us in optimizing query performance along with compute cost.
Client Challenge:
Our client processes millions of records daily and stores them in Databricks Delta lake. There are multiple teams fetching records and data from multiple tables and building golden layer views for further analysis.
One of the team looks at risk management and does deep dive into regulatory compliance. Other teams do some customer behaviour analysis by examining spending patterns.
Few issues faced with traditional approaches (partitioning and Z-Ordering)
- Inconsistent query performance across different query patterns
- High compute costs for complex analyses
- Manual optimization overhead requiring dedicated engineering time
- Storage inefficiencies from frequent OPTIMIZE operations
Steps for Implementing Liquid Clustering
Step 1: Prepare Sample Transaction Data
For our example, we have prepared similar dummy transactions data(~5M records) in Databricks with the help of python libraries.
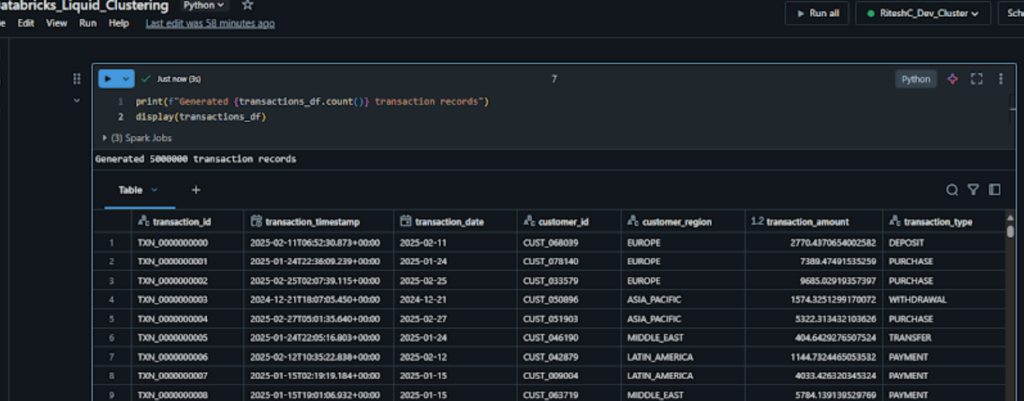
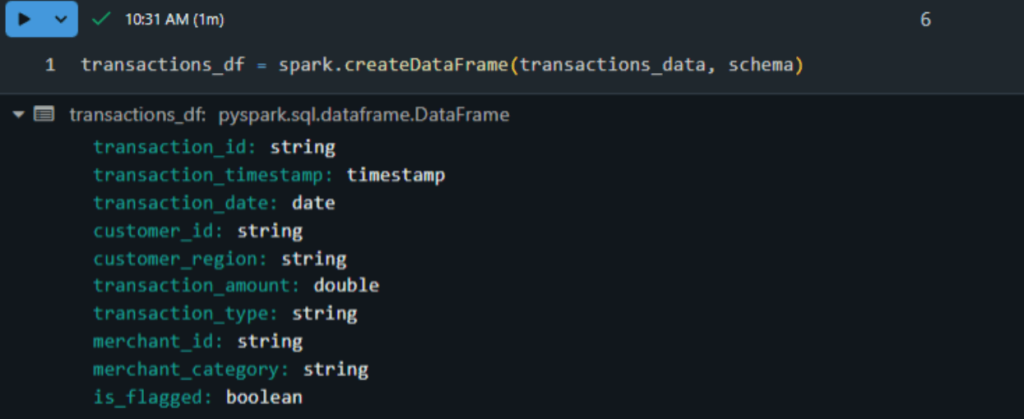
Below is the schema for the data
Step 2: Traditional Approach - Partitioning and Z-Ordering
We created table with partitioned and with Z-Ordering applied on partitioned table.
Table name:: financial_transactions_partitioned_lc_demo
We have highlighted num_files variable that shows 728 files are generated for the table above.
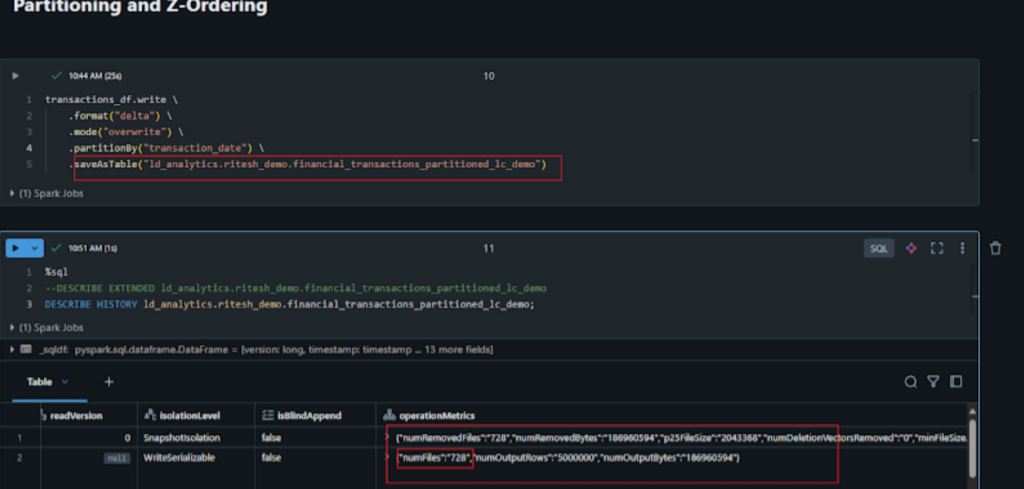
After applying Z-Ordering, let’s see the optimization and data organization effect on partitioned table.
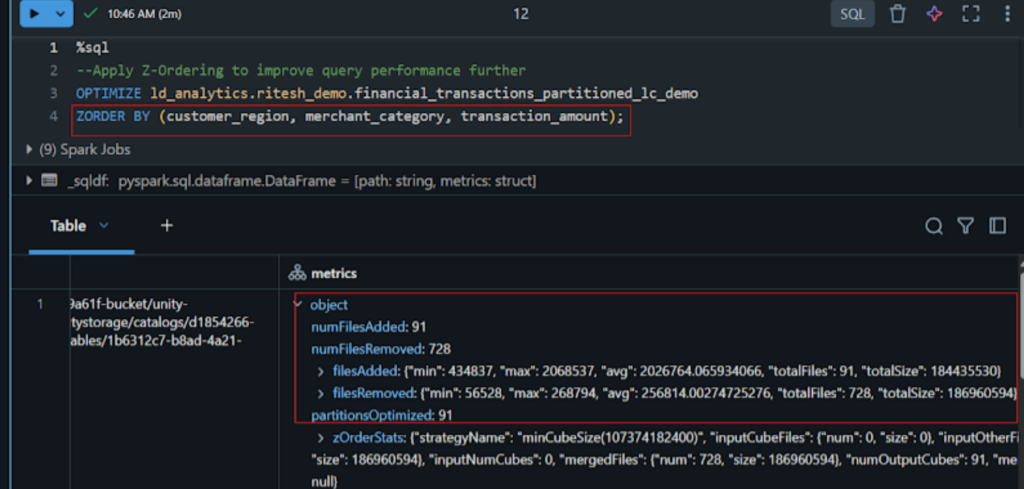
Files were reduced to 91 and partitions optimized 728. This is how Z-ordering helps in data organization and query performance.
Step 3: Implementing Liquid Clustering
Now, let’s implement Liquid Clustering on the same dataset:
We created the below table and added cluster by columns.
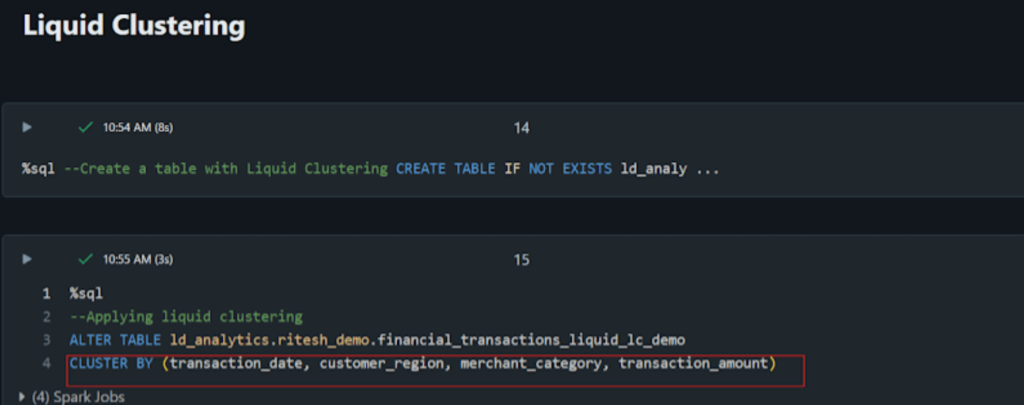
Step 4: Query Performance Comparison
Let’s run some sample queries to compare performance:
We have created a set of queries which mimic the original client queries.
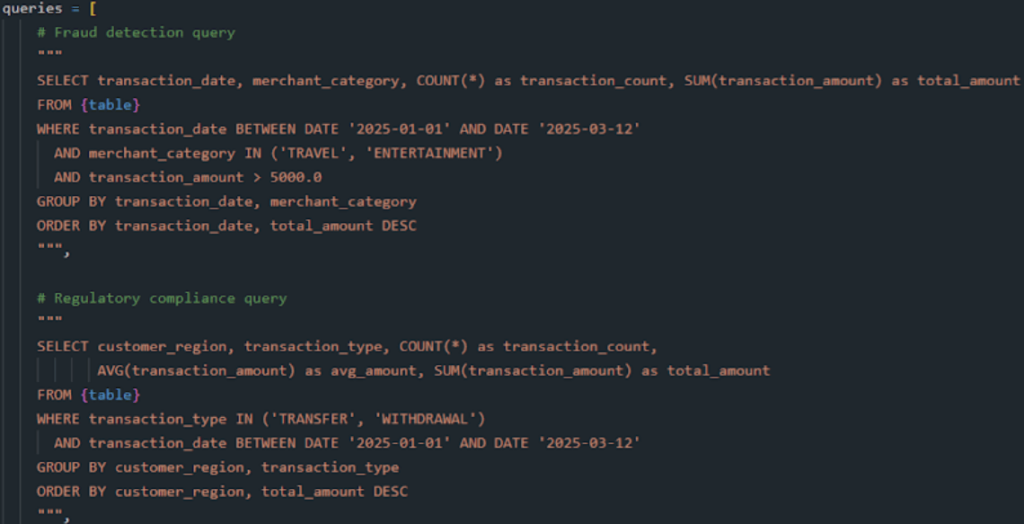
Query 1 -> Fraud Detection Query
Query 2 -> Regulatory Compliance query
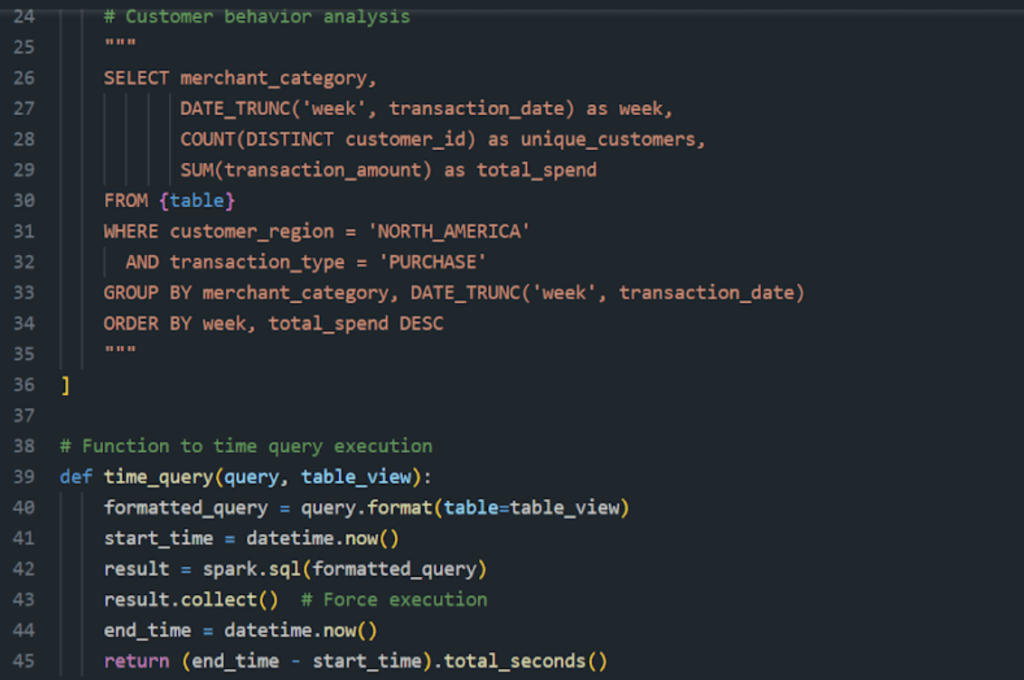
Query 3 -> Customer behaviour analysis query
We are comparing traditional Z-Order with Liquid clustering for each of the query above.
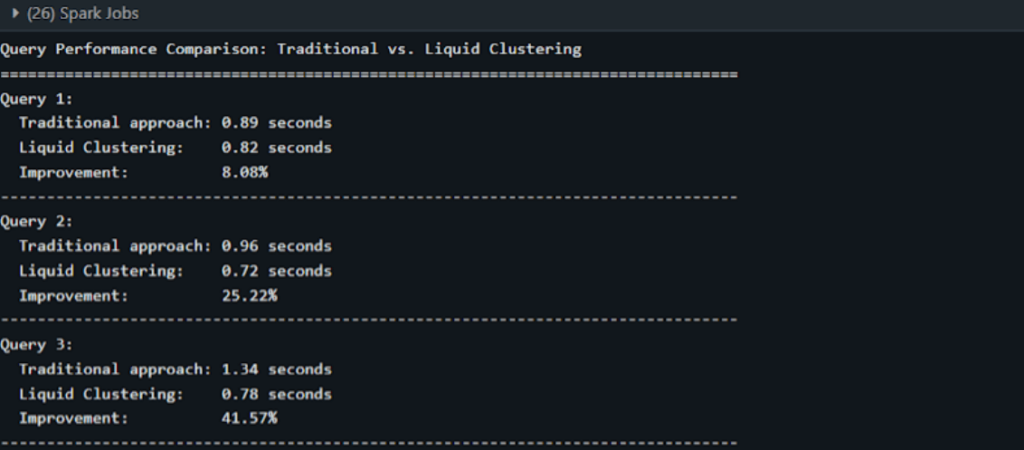
In this implementation, we achieved significant improvement by 40% for query third.
In real-world deployments, Liquid Clustering typically provides:
- 30-60% query performance improvement across diverse query patterns
- 20-40% reduction in compute costs due to more efficient data skipping
- Minimal manual optimization overhead
- Better adaptability to changing query patterns
How Liquid Clustering Works
Liquid Clustering enables:
- Improved Query Performance: Liquid clustering optimizes data layout by reducing number of files improving query performance.
- Automatic File Compaction: It automatically manages and performs file compaction which addresses small file problems (OPTIMIZE Command).
- Multi-dimensional Clustering: It considers multiple columns specified in CLUSTER BY Clause.
How to Choose Between Partitioning, Z-Ordering, and Liquid Clustering
Use Partitioning When:
- Your queries primarily filter on a single high-cardinality column (like date)
- You have well-defined, consistent query patterns
- You need a simple, proven approach
Use Z-Ordering When:
- Your queries filter on multiple columns but in consistent patterns
- You can afford regular OPTIMIZE operations
- You're using older Databricks runtimes that don't support Liquid Clustering
Use Liquid Clustering When:
- Your queries have varied filtering patterns across multiple columns
- You want to minimize manual optimization overhead
- You have large tables (TB+) where traditional optimization is costly
- You need to optimize for both performance and cost
Conclusion
Databricks liquid clustering is a significant advancement in underlying data organization for complex analytical workloads.
For financial institutions that handle billions of records along with complex datasets and diverse query patterns, Liquid clustering is the best solution that offers reduced costs, minimal operational overhead.
Author

Senior Consultant