When your data is scattered across various systems, it becomes a Herculean task to collect, manage, process, and analyze it. This is where the data lakehouse architecture steps in – a modern approach that promises to transform the way businesses handle their data infrastructure. Databricks stands out as the foremost player in the field, offering a unified, open, and scalable lakehouse platform, which we’ll explore in greater detail later in the blog.
By the end of this read, you’ll gain a comprehensive understanding of:
- What is a data lakehouse?
- Data warehouse vs data lake vs data lakehouse
- The different layers of data lakehouse
- Why organizations should opt for the Databricks Lakehouse Platform
What is a data lakehouse?
Recognized as a modern approach to data management, a data lakehouse combines the best features of data lakes and data warehouses. It can be defined as a unified data repository that allows organizations to store raw and structured data in its native format, offering the flexibility of a data lake. Simultaneously, it offers features typically associated with data warehouses such as support for structured data, schema enforcement, maximized query performance, and more.
Databricks defines data lakehouse as “A new, open, data management architecture that combines the flexibility, cost-efficiency, and scale of data lakes with the data management and ACID transactions of data warehouses, enabling business intelligence and machine learning on all data.”
Here’s how Gartner defines it:
“Data lakehouses integrate and unify the capabilities of data warehouses and data lakes, aiming to support artificial intelligence, machine learning, business intelligence, and data engineering on a single platform.”
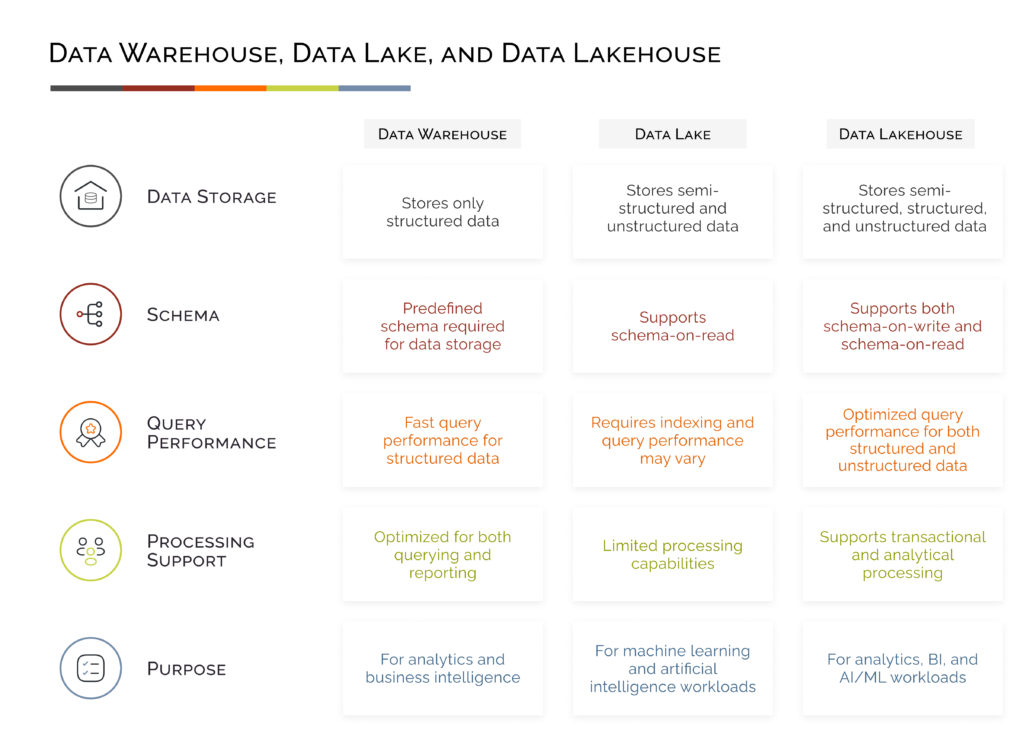
A quick summary of how a data warehouse, a data lake, and a data lakehouse are distinct from each other:
Layers of data lakehouse
Each layer of the data lakehouse serves a specific purpose. Here’s how:
1. Ingestion layer
This is the layer where data from external systems, IoT devices, relational and NoSQL databases, or streaming platforms is collected and ingested into the lakehouse. It involves the ETL process to prepare the data for storage and analysis.
2. Storage layer
This layer stores raw and processed data forms, using cloud-based storage services like Amazon S3, Azure Data Lake Storage, or others. Your data is typically stored in open and flexible formats such as Parquet, ORC, or Avro.
3. Processing layer
The processing layer prepares, transforms, and enriches raw data for analysis and reporting. Enrichment means adding more context to the existing data. For instance, customer data is enriched by adding detailed information like demographics and location information. Batch and real-time data processing is performed using technologies such as Apache Spark.
4. Metadata layer
This layer tends to maintain the metadata information about your data’s source, schema, lineage, and other relevant attributes. You can call it a catalog or index of the data assets available in the lakehouse, providing dataset description and making it easier for users to comprehend the information. Modern data tools often integrate with this layer to support features like data lineage visualization, automated data discovery, and more.
5. Query and Analytics layer
This is the topmost layer where all your users, including data analysts, data engineers, data scientists, and business stakeholders, interact with the data. modern tools are used to access and query the data stored in the lakehouse. Users can build and execute ML models to extract insights. Also, data access controls, authentication, and authorization mechanisms are implemented within this layer.
Optimize your data value with Databricks
Founded by the creators of Apache Spark, Delta Lake, and MLflow, Databricks is a cloud-based data analytics platform that offers a unique combination of data engineering, data science, and machine learning capabilities. In 2023, Databricks has seen widespread adoption as a leading big data analytics tool, with more than 9,844 companies worldwide embracing its capabilities. The majority of these organizations – around 46.65% are from the United States, highlighting the platform’s strong presence in the U.S. market.
The Databricks Lakehouse Platform represents a groundbreaking approach to modern data management, unifying data, analytics, and artificial intelligence on one platform. It is built on opensource technologies and adheres to open standards. This means that the platform uses communitysupported tools and frameworks, facilitating interoperability.
Let’s see how the Lakehouse Platform simplifies your data ecosystem:
• Leverage a unified platform
The Databricks Lakehouse Platform consolidates data integration, storage, processing, governance, sharing, analytics, and AI into one cohesive platform. It streamlines how you handle both structured and unstructured data, providing a single, end-to-end perspective on data lineage. Databricks’ Lakehouse solution provides you with a unified toolset for Python and SQL, support for notebooks and IDEs, and the ability to handle both batch and streaming data across major cloud providers.
• Experience unmatched scalability
With automatic optimization for performance and storage, Databricks is one of the most costeffective data lakehouse platforms available. It provides you with generative techniques like large language models. LLMs can continuously adapt content based on the most up-to-date information available.
• Gain access to Delta Tables and Unity Catalog
With Databricks, you get access to powerful components that empower organizations to streamline data management, governance, and collaboration. The Delta Tables component provides you with sub-components, such as ACID Transactions, Data Versioning, ETL, and Indexing. Get data integrity and consistency assurance with ACID (Atomicity, Consistency, Isolation, Durability) transactions, and ensure reliable data processing. You can optimize query performance and access data faster through indexing. Unity catalog involves data governance, data sharing, and data auditing. Databricks’ Catalog Explorer is a user-friendly data discovery interface that helps explore and manage data, schemas, tables, and permissions. Also, the data audit component enables admins to access details about dataset access and actions taken by users.
Conclusion
Databricks provides you with an unparalleled platform for analyzing data within a lakehouse environment. Its ease of use empowers your business to tackle data challenges head-on.
Here at LumenData, we take pride in being a part of the trusted Databricks partner network. Our expert team can assist you in formulating a data strategy that aligns with Databricks’ cutting-edge capabilities. Initiate a conversation today and take your first step toward implementing a modern, scalable data lakehouse platform.
Reference links:
- https://www.gartner.com/en/documents/4010269
- https://www.databricks.com/glossary/data-lakehouse
- https://6sense.com/tech/big-data-analytics/databricks-market-share#:~:text=Databricks%20has%20market%20share%20of,Synapse%20with%2012.47%25%20market%20share
- https://www.databricks.com/
- https://docs.databricks.com/en/lakehouse/acid.html
- https://docs.databricks.com/en/data-governance/index.html
Authors:

Shalu Santvana
Content Crafter

Mohd Imran
Senior Consultant
Mohd Imran
Senior Consultant
Shalu Santvana
Content Crafter