Businesses today are leaning heavily on data-driven initiatives to fuel their growth. Modern data platforms are the perfect toolbox that securely stores their datasets and takes care of all their sensitive information from start to finish.
Think of your favorite OTT platform delivering personalized recommendations right when you need them. The seamless experience isn’t magic; it is powered by robust data platforms that intelligently collect, process, and analyze large datasets in real-time. The blog piece will look at the meaning of a modern data platform, its components, and best benefits. We’ll also mention the capabilities of a few modern data platforms like Snowflake, Informatica, and Databricks.
What is a Modern Data Platform?
A modern data platform, also known as a modern data stack, is defined as the foundational layer upon which various data tools and applications operate. It is crafted to be inclusive, forward-looking, adaptable, and agile, catering to the unique requirements of contemporary business teams. Modern data platforms are software solutions designed with a cloud-first approach, meaning they are optimized for cloud environments from the beginning. The cloud-native tools facilitate your organization’s data gathering, cleaning, processing, and analysis processes.
Modern data platforms are designed to separate storage and computing functions, enabling organizations to efficiently store large data volumes at a relatively low cost. They can adjust computing resources automatically. So, in case there’s a surge in demand for processing data, the system can instantly increase its computing potential. Likewise, when the demand decreases, it scales back down. This flexibility is one of the top principles of a modern data platform which ensures that resources are utilized optimally to provide a responsive experience without any unnecessary expenditure.
Components of a Modern Data Platform
A modern data platform is said to have five critical foundational layers. Let’s go over them one by one:
1. Data Storage and Processing
For data storage, there are four different formats that we can talk about: data warehouse, data lake, data lakehouse, and data mesh. However, you must note that data architectures like lakehouse and data mesh are emerging concepts and are gaining popularity as more organizations seek integrated, scalable, and agile solutions to address data challenges.
(a) Data Warehouse
It is specifically designed for storing structured data optimized for analytical querying and reporting. Data warehouses utilize a schema-on-write approach. This means that the data is structured and organized before being loaded into the warehouse. Such an approach accelerates query performance and analytical processing.
Google defines data warehouse as “an enterprise system used for analysis of structured and semi-structured data from multiple sources, such as point-of-sales transactions, marketing automation, customer relationship management, and more.”
Businesses can consider leveraging Snowflake for their modern data warehousing requirements. Its unique, multi-clustered architecture separates computing and storage, allowing each to scale independently. Queries can smoothly without disruptions, as compute resources automatically adjust based on workload demands.
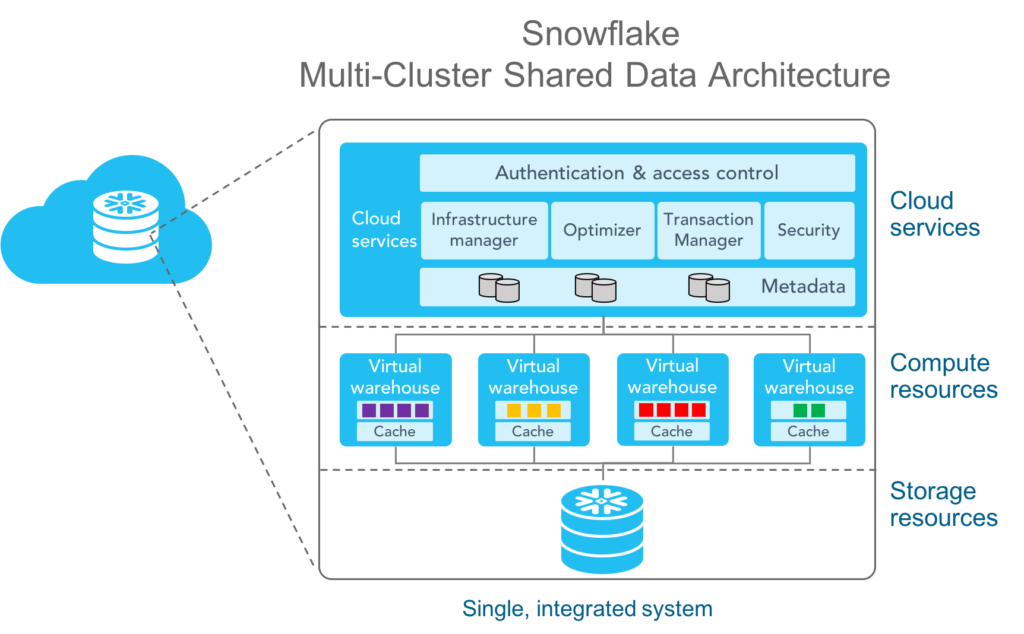
Image Source: Snowflake
(b) Data Lake
It is designed to store raw, semi-structured, and unstructured data at scale. Data lakes leverage a schema-on-read approach. This means that they allow data to be stored in its native format without any predefined structures. Businesses can store data quickly without upfront transformation. They can analyze the information later based on their specific needs.
(c) Data Lakehouse
Data Lakehouse is the perfect combination of a data warehouse and a data lake. It provides businesses with a unified platform for storing and analyzing structured, semi-structured, and unstructured data.
As data lakehouses tend to integrate data storage and computing, businesses can reduce data movement and accelerate time-to-insight.
Organizations can consider using the Databricks Lakehouse architecture that encompasses integration, storage, processing, and analytics for both structured and unstructured data.
You get a comprehensive view of data lineage and provenance. Databricks supports Python and SQL across notebooks, IDEs, batch and streaming workflows. Moreover, it promotes an open environment, ensuring that your data remains free from proprietary formats and locked ecosystems.

Image Source: Databricks
(d) Data Mesh
It is a decentralized approach to data architecture that emphasizes domain-oriented, self-serve data infrastructure, and governance. Data mesh tends to decentralize data ownership, management, and consumption across various business units.
The next component that we’ll be talking about is data processing. Let’s take a quick look at the two categories:
(a) Batch Processing
It involves the processing of large data volumes at specific time periods or scheduled intervals. Batch processing enables organizations to perform data transformations, aggregations, and analytics on historical datasets.
(b) Stream Processing
Stream processing will facilitate real-time data processing, analysis, and visualization by processing data streams as they are ingested into the system.
2. Data Ingestion
Data Ingestion is the initial step in the data lifecycle and is a critical component of a modern data platform. Data Ingestion mechanisms will capture data from a wide range of sources, including databases, enterprise applications, social media platforms, IoT devices, and more. Ingestion processes will handle both structured and unstructured data. Structured data will include tables, rows, and columns while unstructured data will include texts, images, videos, and logs.
The Informatica Intelligent Data Management Cloud Platform simplifies the process of ingesting and replicating enterprise data. It enables organizations to handle various data ingestion methods such as batch processing, streaming, real-time data transfer, and change data capture. A modern data platform like Informatica can provide organizations with modern ingestion tools and services that offer various advantages, as shown in the picture below:

Image Source: Informatica
3. Data Transformation
Data Transformation involves the process of converting data from one format or structure into another to make it suitable for various operational and analytical processes. It facilitates data integration, cleansing, enrichment, and standardization. ETL processes are a fundamental part of data transformation. Data is extracted from various sources and transformed into a consistent format or structure. It is then loaded into a modern data warehouse or target system.
Modern data platforms leverage advanced ETL and data preparation tools that provide graphical interfaces, predefined transformations, and automation capabilities. Data pipeline orchestration comes under data transformation. Complex data pipelines are orchestrated to automate workflows across various systems and environments.
4. Analytics and Business Intelligence
Analytics will involve systematic exploration, communication, and analysis of datasets to discover different patterns, trends, and correlations. Business intelligence involves the tools, applications, and methodologies that facilitate visualization, reporting, and sharing of insights in intuitive dashboards. Stakeholders across different business units can interpret data effortlessly.
5. Data Observability
It is the ability to comprehend what is happening within a data system by observing its outputs, behaviors, and processes. Data observability is not limited to data monitoring. It involves capturing detailed records of data operations, queries, and changes. It also includes providing notifications and alerts for unexpected issues in the data pipelines. The data observability component within a modern data platform streamlines various aspects of enterprise data like:
- Timeliness – Is the data up-to-date? When was it last sourced? Which preceding information is left out?
- Completeness – Is the received data integrated into the system?
- Consistency – Is the data correctly structured and is it aligning with expected patterns?
- Structure – What sort of modifications have been made to the data’s format? Who initiated these changes and for what objectives?
Apart from the five foundational layers/components of modern data platforms discussed above, there are some additional critical components such as data governance, data discovery, data cataloging, machine learning and artificial intelligence, and more.
Benefits of a Modern Data Platform
A modern data platform enables organizations to seamlessly integrate, oversee, and deliver data at the right time and location. Businesses should consider implementing a modern data platform because it:
Supports different data types, formats, and sources.
Scales quickly to accommodate growing data volumes and user demands.
Offers best-in-class data governance and security features, enabling compliance with industry regulatory standards.
Allows customized integration with existing systems and technologies based on unique business requirements.
Minimizes downtime and data loss risks through distributed architectures and data replication capabilities.
Supports advanced analytics including machine learning, artificial intelligence, and predictive analytics to drive faster insights.
Wrapping Up
Leveraging the right data platform is pivotal for your organizational growth and innovation. Here, at LumenData, we have a deep understanding of modern solutions. With strong partnerships with industry leaders like Informatica, Snowflake, Reltio, and Databricks, our consultants can help make and implement informed choices. Connect today to discuss ways that can make your data journey smoother!

Shalu Santvana
Content Crafter

Mohd Imran
Senior Consultant