Share this on:
LinkedIn
X
When large volumes of data are processed in small amounts of time, it’s called batch processing. Please note that data is collected, stored, and processed in batches at scheduled intervals. Simply put, as per AWS, computers use the batch processing method to periodically complete high-volume, repetitive data jobs.
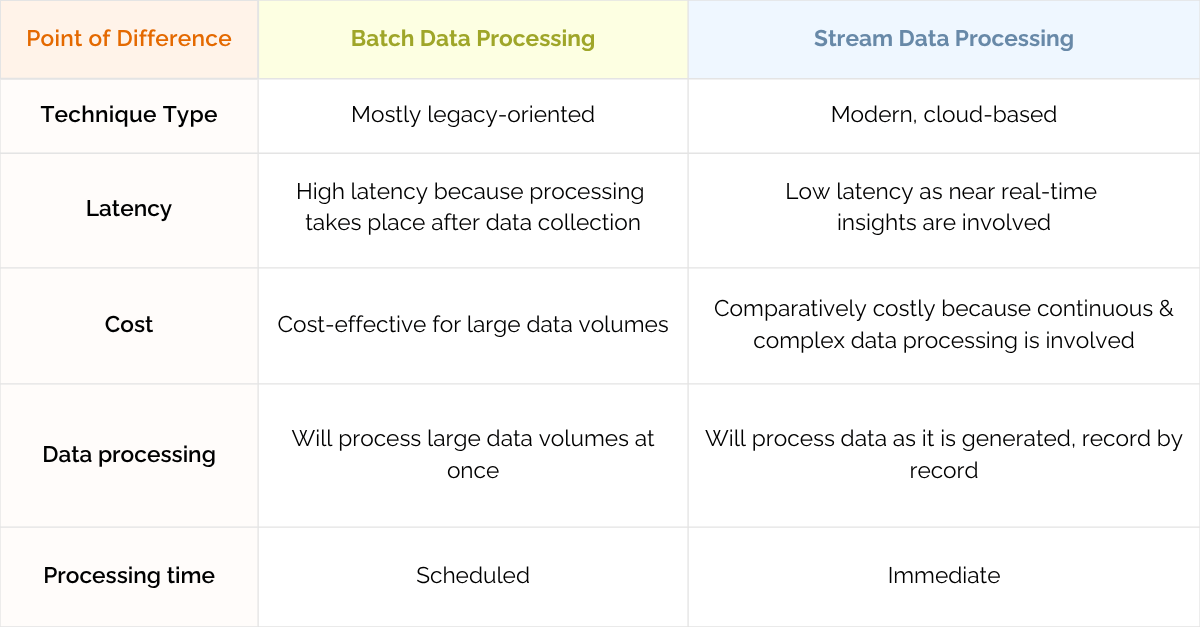
Batch Data Processing vs Stream Data Processing
Batch Data Processing Technology
Some of the most popular technologies for batch data processing include Apache Spark, Apache Hadoop, Apache Flink, Google Cloud Dataflow, AWS Batch, Microsoft Fabric, Apache Airflow, & more.
How Batch Data Processing Works
- Step 1: Data is collected from different sources and then stored.
- Step 2: All jobs are grouped into batches. This is based on the data type and processing requirements.
- Step 3: The batches are processed one by one – depends on the system capacity.
- Step 4: Once the processing is done, the result is shared with relevant stakeholders.