Share this on:
What You'll Learn
This blog covers our recent deployment where we used Snowflake’s native task orchestration feature to address issues in data pipeline maintenance for a customer. Learn how we provided a more streamlined, economical solution for our customer.
Client Challenges
Our customer, an expanding e-commerce business, was facing multiple pain points in their current data pipeline infrastructure.
- Complex Dependency Management: Their multi-dimensional data model needed careful sequences of updates to ensure data integrity with customer, product, and date dimensions driving into a sales fact table.
- Operational Overhead: 3rd party orchestration tools needed more than one system to be integrated which, in turn, added operational overhead along with management of several other systems. It also required them to store and manage credentials and connections.
- Monitoring Challenges: One of the major challenges clients faced was debugging of pipeline failures. As errors and execution traces were dispersed across multiple platforms, it took longer time to debug and find root cause analysis.
- Cost Inefficiency: Involvement of third-party orchestration tools along with Snowflake compute added cost burden to client.
- Maintenance Burden: Third party orchestration tools required specific expertise which caused bottlenecks while new enhancements and development.
LumenData’s Approach and Snowflake-Native Solution
After understanding and evaluating client requirements, we developed our own custom Snowflake native solution.
Our Snowflake native solution and architecture is centred around the following key components:
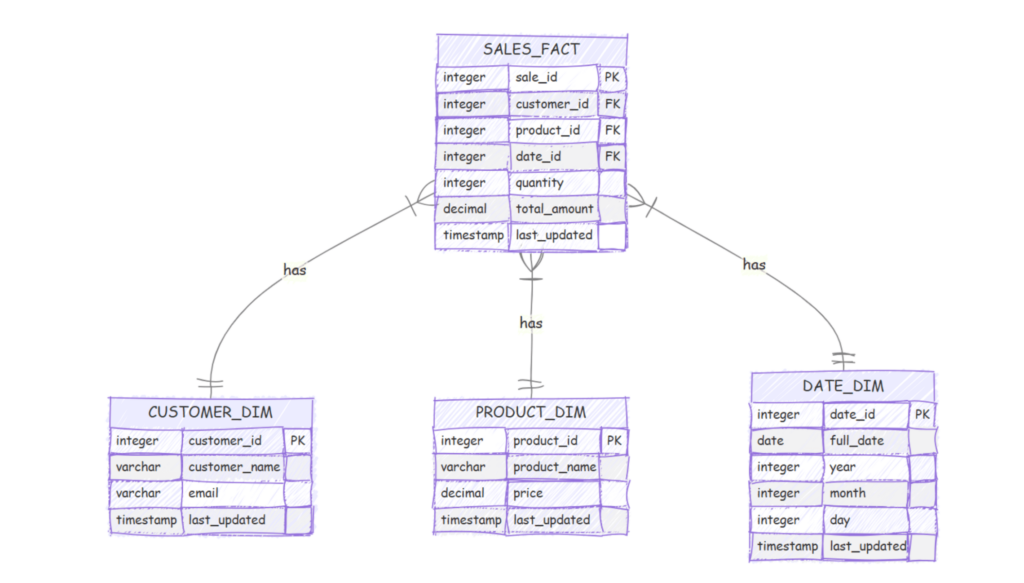
1. Dimensional Data Model
We refactored and enhanced the client’s dimensional model with a standard star schema which included three dimensional and one fact table.
(Note: all examples and models are for reference purpose and are like client data model)
Customer Dimension
Stores customer profiles and attributes
Product Dimension
Contains product details and pricing information
Date Dimension
Maintains a comprehensive date hierarchy
Sales Fact
Captures transactional data connected to the dimensions
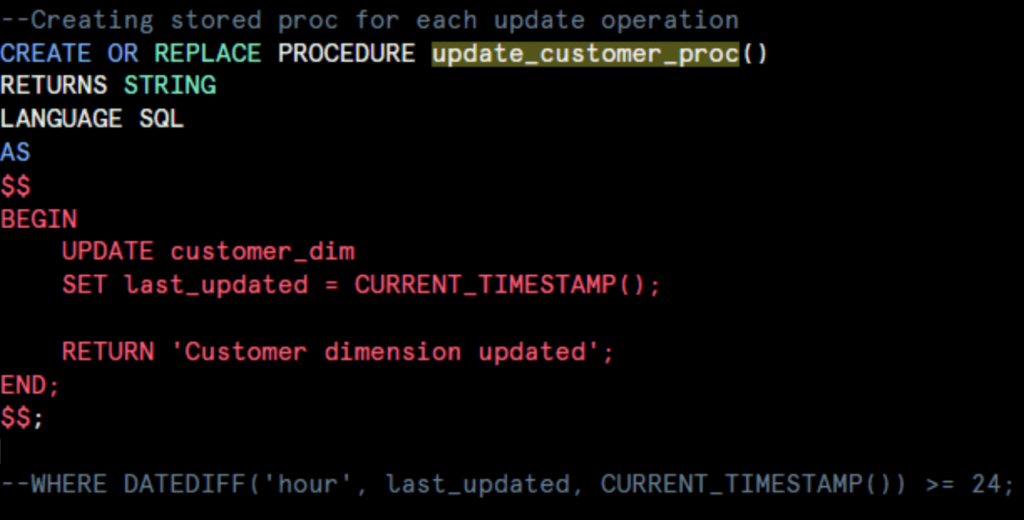
2. Stored Procedures for Data Update
For each update operation, we created dedicated stored procedures
update_customer_proc():
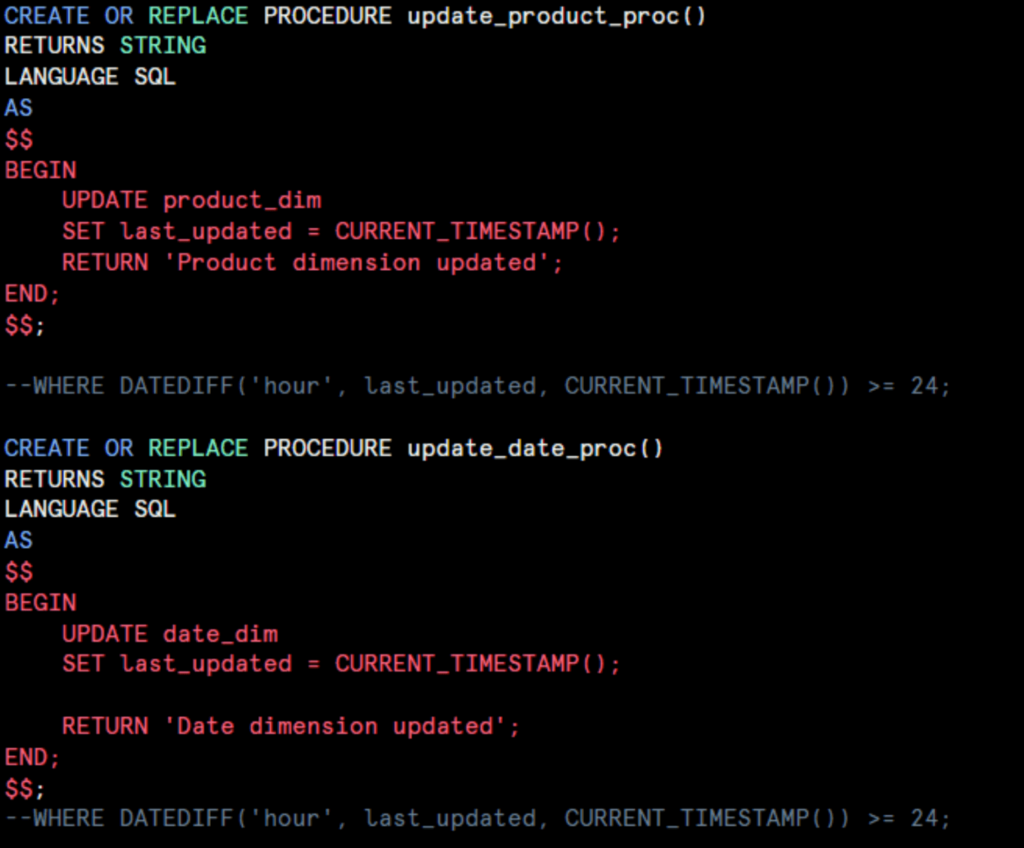
Similar procedures were created for product and date dimensions. Plus, an aggregation procedure for the sales fact table:
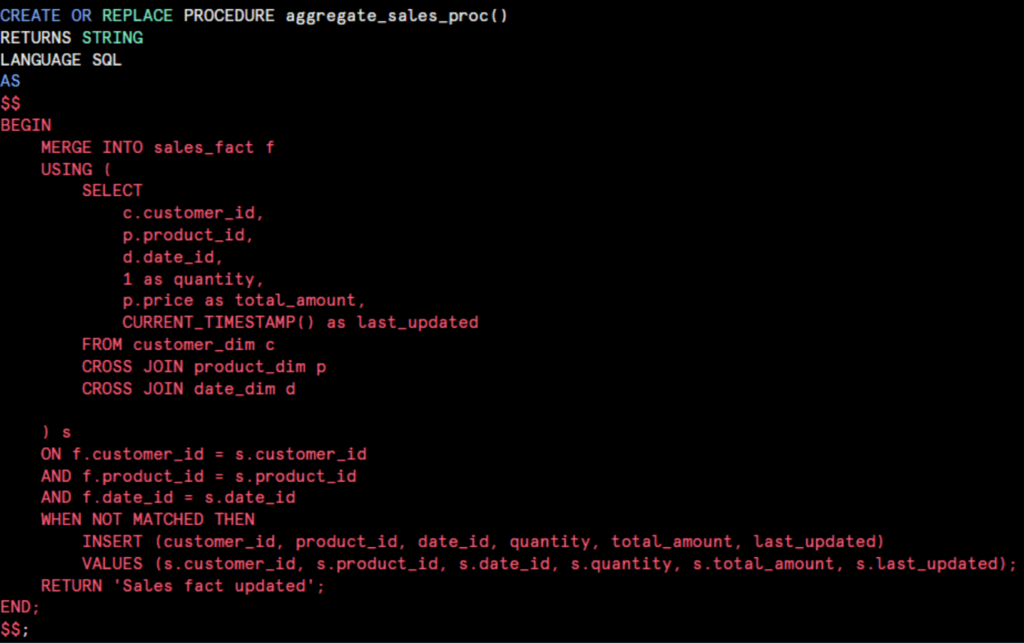
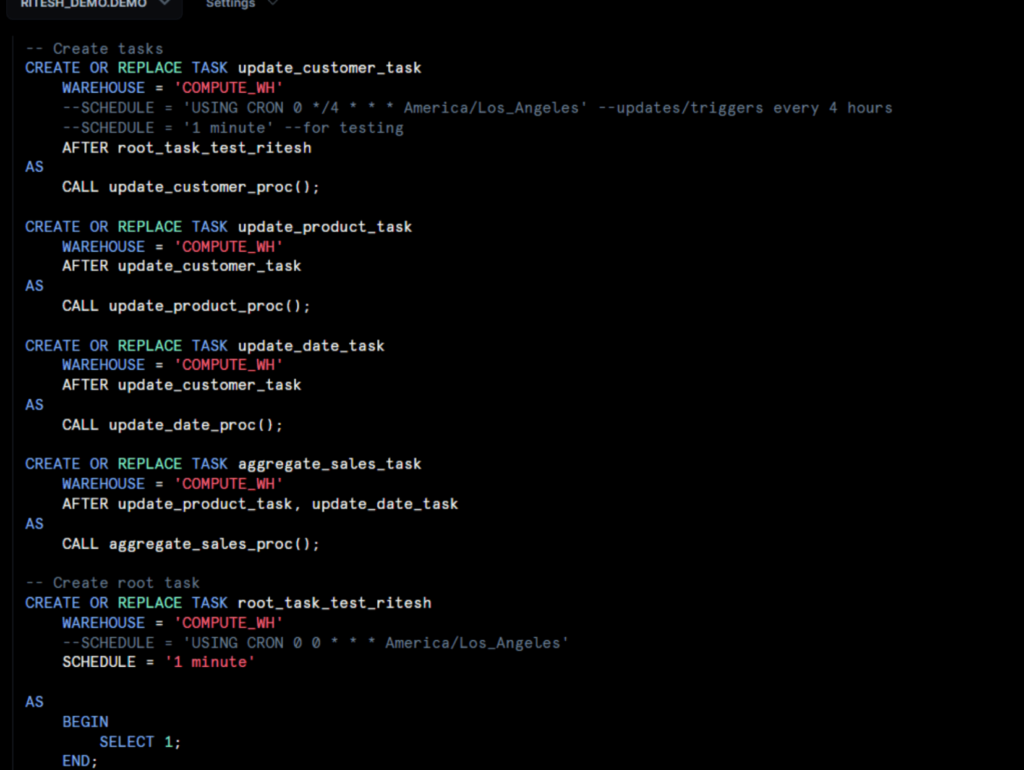
3. Task Orchestration with Dependencies
The core centre of our solution was a task framework that was hierarchical and helped us in managing execution dependencies. We can leverage CRON scheduling with Snowflake tasks. It is more helpful and efficient in scheduling and orchestration.
For testing and demo purpose, we have commented out the code and used hardcoded 1 minute as pipeline schedule.
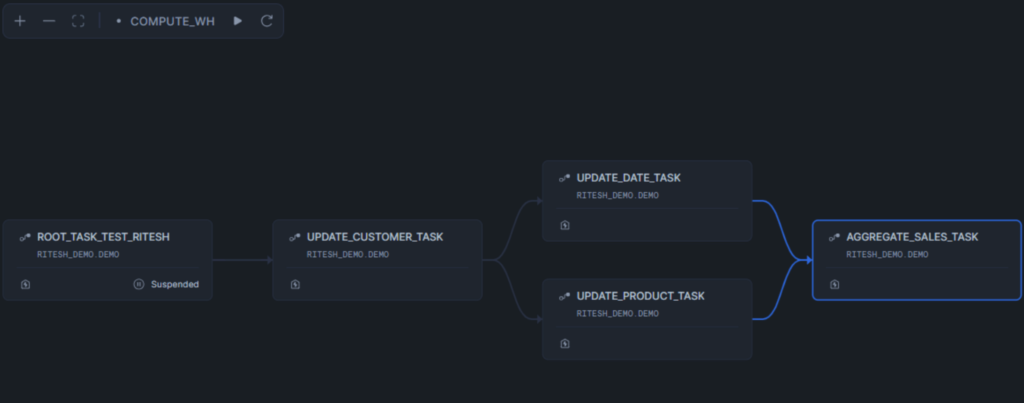
This created a directed acyclic graph (DAG) of dependencies:
- The root task acts as the scheduler, triggering at defined intervals
- Customer dimension will be updated first
- Product and date dimensions are updated in parallel after the customer dimension
- Sales fact aggregation runs only after both product and date dimensions are updated
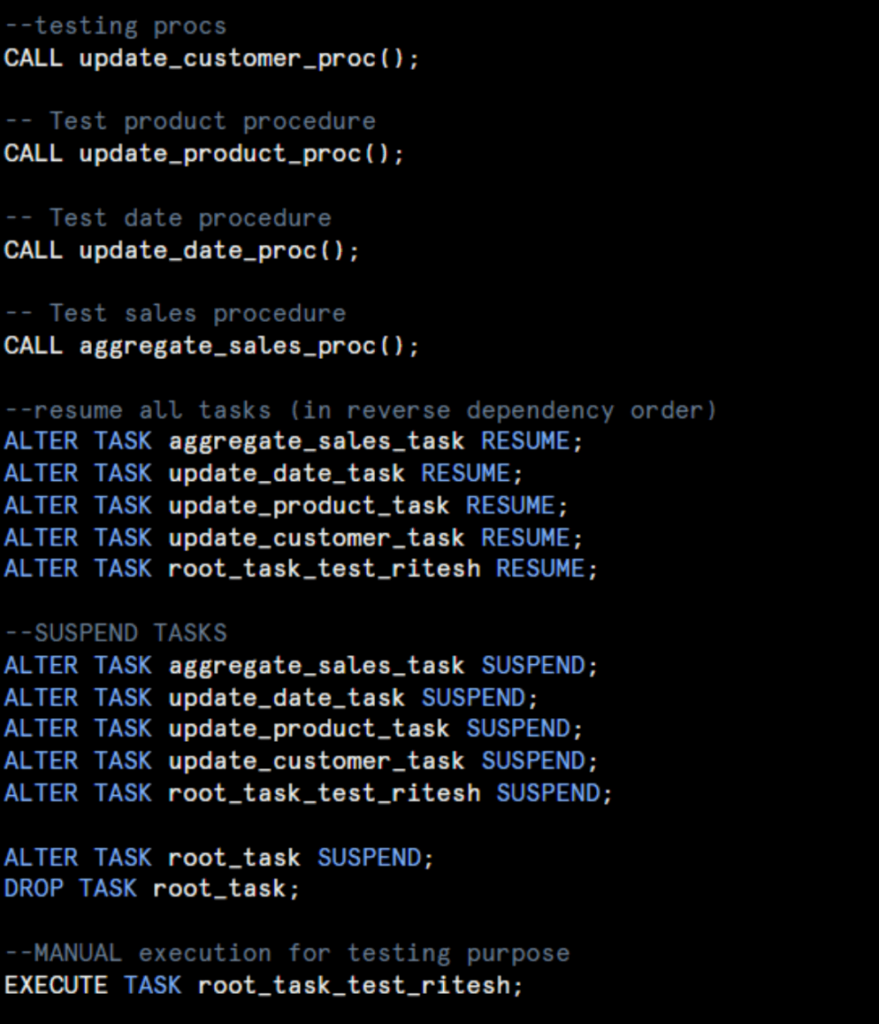
Testing Commands
Below are testing commands for reference:
RESUME TASKS -> Starts/Resumes the tasks
SUSPEND TASKS -> Pauses/Suspends tasks
Manual Execution command for testing workflow/pipeline:
EXECUTE TASK root_task_test_ritesh;
4. Monitoring and Debugging
With this approach, we have seen significant advantages along with comprehensive monitoring and debugging.
Centralized Task History: Snowflake provides built-in task execution history through the INFORMATION_SCHEMA:

This provides a 360-degree visibility into:
Task Execution Times
Run Duration
Success/Failure Status
Error Messages
Dependencies & Triggers
All this information is available in one place without needing to correlate logs across multiple systems.
Alternatively, you can leverage Snowflake Snowsight UI to check individual task runs.
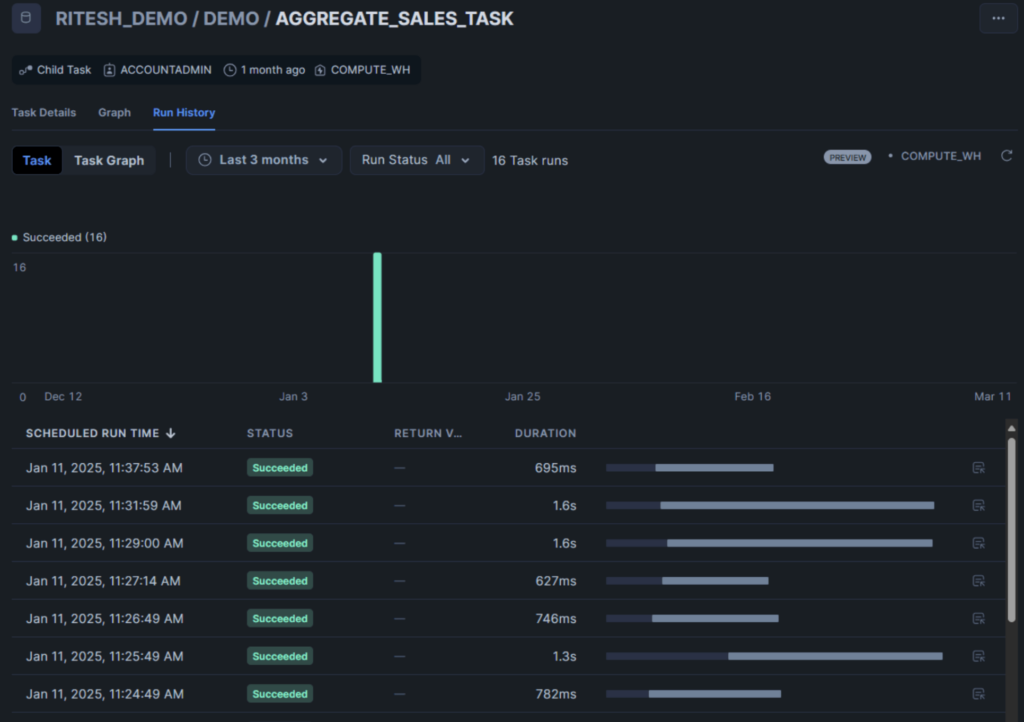
Real-Time Status Monitoring: The client’s team can now monitor pipeline status in real-time through simple SQL queries:
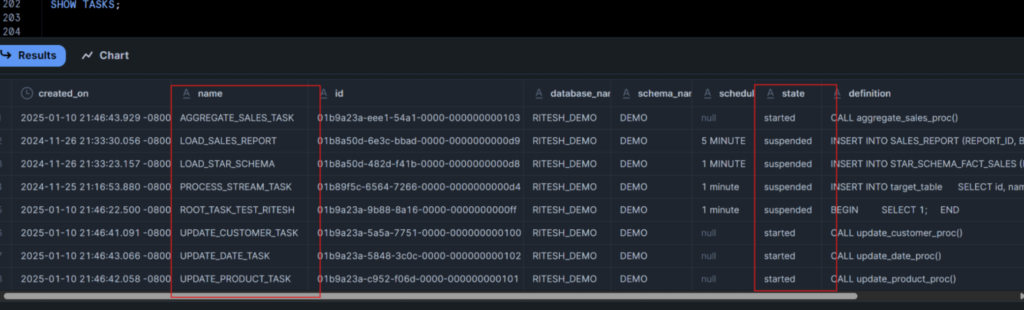
SHOW TASKS;
This provides immediate visibility into:
What Tasks are Currently Running
What Tasks are Scheduled
What Tasks Suspended Due to Issues
Historical Performance Analysis: Our Snowflake native solution helps the client in performing historical analysis.
This would include:
Identifying tasks that are taking longer than expected
Identifying recurring patterns in failures
Optimizing warehouse sizing based on actual resource usage
5. Further Developments
We are now building a Streamlit based UI dashboard for self-service troubleshooting and proactive monitoring. It consolidates and captures details from Task History.
This helps the client team to manually execute the SQL commands in Snowflake environment and get the details directly from the Streamlit UI Dashboard.
Furthermore, we are integrating email notification and Microsoft Teams notifications for proactive monitoring of pipeline failures.
Check out our implemented solutions here:
6. Key Takeaways
- Leveraging Snowflake native capabilities and keeping orchestration within the data platform reduces complexity, cost, and potential failures
- Our solution offers centralized monitoring and management that reduces operation overhead along with faster resolution of pipeline failures.
- By deciding right sized compute resources and removing external 3rd party tools costs, you drive meaningful financial benefits.
About LumenData:
LumenData is a leading provider of Enterprise Data Management, Cloud and Analytics solutions and helps businesses handle data silos, discover their potential, and prepare for end-to-end digital transformation. Founded in 2008, the company is headquartered in Santa Clara, California, with locations in India.
With 150+ Technical and Functional Consultants, LumenData forms strong client partnerships to drive high-quality outcomes. Their work across multiple industries and with prestigious clients like Versant Health, Boston Consulting Group, FDA, Department of Labor, Kroger, Nissan, Autodesk, Bayer, Bausch & Lomb, Citibank, Credit Suisse, Cummins, Gilead, HP, Nintendo, PC Connection, Starbucks, University of Colorado, Weight Watchers, KAO, HealthEdge, Amylyx, Brinks, Clara Analytics, and Royal Caribbean Group, speaks to their capabilities.
For media inquiries, please contact: marketing@lumendata.com.
Authors

Content Writer

Senior Consultant