Share this on:
What You'll Learn
Choosing the right architecture for your data needs is a crucial first step in launching your project. There are several ETL data architectures available to meet different business requirements and data complexities.
This technical blog series consists of two parts:
- The first part covers commonly used data architecture in Databricks such as the Medallion Architecture, Lambda Architecture, and Kappa Architecture, which we have implemented for various clients.
- The second part consists of a few more commonly used data architectures across the data industry such as Data Vault Architecture, Kimball’s Dimensional Data Warehouse, Inmon’s Corporate Information Factory, and Lakehouse Architecture.
Databricks Data Architectures
1. Medallion Architecture
The Medallion Architecture is a structured method for data processing commonly used in data lakes.
It tackles the challenges of handling vast amounts of varied data by categorizing it into increasingly refined layers.
The main goal is to enhance data quality and traceability while establishing a clear framework for data governance.
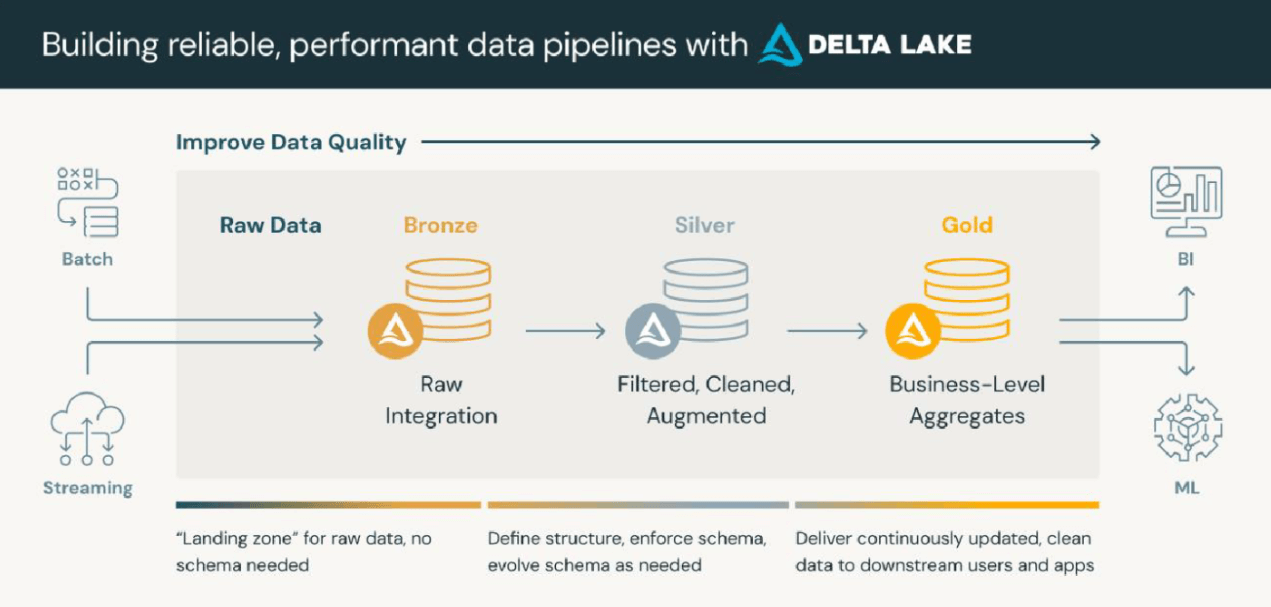
Bronze Layer
The first layer of data ingestion is the Bronze Layer.
In this layer, raw data is collected from a source that includes point-of-sale systems, online transactions, IoT devices, and other data-generating systems.
This raw data is kept in its original format within a data lake so that large volumes of diverse data types can be stored without immediate transformation.
Silver Layer
The Silver Layer is focused on cleaning and enriching the raw data gathered during the Bronze Layer. Here, the data undergoes a sequence of processes meant to enhance its quality and usefulness.
These involve removing duplicates, standardizing the format of the data, correcting errors, and appending additional contextual information, such as customer demographics or product metadata.
Gold Layer
The Gold Layer is the last layer in the Medallion Architecture, where data is aggregated & refined for specific business applications. This layer is committed to creating business-specific datasets optimized for reporting, dashboarding, and advanced analytics.
The data is very curated and sometimes tailored to suit the needs of different business units, such as finance, marketing, & operations.
2. Lambda Architecture
The Lambda Architecture is a data processing framework that effectively manages large volumes of data by combining batch and real-time processing techniques.
It meets the demand for real-time analytics while also enabling thorough analysis of historical data.
This architecture is especially useful in situations where both quick updates and extensive data processing are necessary.
Lambda Architecture consists of three primary components: the Batch Layer, the Speed Layer, and the Serving Layer.
Each component has a distinct function that ensures data is processed efficiently.


Batch Layer
The Batch Layer processes and stores vast amounts of historical data.
It performs extensive data processing operations that can handle higher latencies, like calculating long-term aggregates, trends, and patterns.
The outcome is stored in a batch view, which presents a unified view of the historical information.
Speed Layer
The Speed Layer, however, deals with real-time data streams, processing the latest data as soon as it is available. This component complements the Batch Layer to produce immediate insights and updates based on the most recent data.
Typically, the Speed Layer is built using stream processing frameworks such as Apache Storm, Flink, or Kafka Streams. The objective of the Speed Layer is to process real-time data as fast as possible while producing incremental updates that can be merged with the batch view within the Serving Layer. This will ensure that both the latest and historical data that have been processed by the Batch Layer are made available to users.
Serving Layer
The final layer is the Serving Layer, which combines both batch view and real-time view.
This layer makes it possible for queries to have access to historical as well as real-time data, allowing users to conduct complex analytical tasks.
It integrates the outputs coming from the Speed Layer and Batch Layer, bringing about the idea of the Serving Layer to facilitate better query performance.
In return, this will allow the extraction of valid information from the source, despite unknown origin.
3. Kappa Architecture
The Kappa Architecture is a simplification of the Lambda Architecture but is designed specifically for real-time data processing. It does not include batch processing but focuses solely on the processing of data streams in real-time.
This architecture is ideal for situations where there is no need to process historical data, with an emphasis on low-latency ingestion and processing of data. Kappa Architecture aims to simplify the entire data pipeline and, by providing a single stream layer for consumption, processing, and storage.
This would solve the problems relating to handling one batch layer in addition to at least one speed layer and its complexity when compared to others.

Streaming Layer
The Streaming Layer is one of the key components of the Kappa Architecture, responsible for real-time ingestion and processing of data.
It uses stream processing frameworks like Apache Kafka, and Apache Flink, to handle continuous data streams.
The main role of the Streaming Layer is to handle incoming data events as they happen, performing transformations and computations in real-time.
This approach guarantees that data is processed with minimal delay and is readily available for immediate use.
Serving Layer
The Serving Layer of the Kappa Architecture provides a real-time view of the processed data.
It holds the output from the Streaming Layer and enables real-time queries and analytics.
This layer is designed to support high query volumes with rapid response times.
The Streaming Layer and the Serving Layer are linked, ensuring that the users are always accessing the most recent data.
This ensures that real-time decision-making and analytics are possible.
Lumendata’s Architecture Selection Guidelines
At LumenData, we extensively work with the Databricks platform, implementing the above data architectures for clients. Listed below are a few guidelines for selecting correct and suitable architecture depending on use cases.
Select Medallion Architecture When:
- Data quality and governance are paramount
- Multiple teams need access to different levels of data quality
- You need transparent data lineage and audit trails
Select Lambda Architecture When:
- Both real-time & batch processing are critical
- You require high accuracy for historical analysis
- Real-time views can tolerate some approximation
- Resources are available to maintain parallel systems
Select Kappa Architecture When:
- Stream processing can handle your data volume
- Real-time processing is the primary requirement
- You want to minimize system complexity
- Batch processing requirements are limited
About LumenData:
LumenData is a leading provider of Enterprise Data Management, Cloud and Analytics solutions and helps businesses handle data silos, discover their potential, and prepare for end-to-end digital transformation. Founded in 2008, the company is headquartered in Santa Clara, California, with locations in India.
With 150+ Technical and Functional Consultants, LumenData forms strong client partnerships to drive high-quality outcomes. Their work across multiple industries and with prestigious clients like Versant Health, Boston Consulting Group, FDA, Department of Labor, Kroger, Nissan, Autodesk, Bayer, Bausch & Lomb, Citibank, Credit Suisse, Cummins, Gilead, HP, Nintendo, PC Connection, Starbucks, University of Colorado, Weight Watchers, KAO, HealthEdge, Amylyx, Brinks, Clara Analytics, and Royal Caribbean Group, speaks to their capabilities.
For media inquiries, please contact: marketing@lumendata.com.
Authors

Senior Consultant