Snowflake is an intuitive, managed SaaS that provides a single platform for data warehousing, data lakes, and data engineering popular for its ability to support multi-cloud infrastructure environments. The following blog explains the techniques for optimizing snowflake performance on the data cloud.
“Founded in 2012 and publicly launched in 2014, Snowflake has grown to become one of the world’s largest cloud vendors by revenue as of 2022”- Statista.
What is Snowflake data cloud service ?
The Snowflake on data platform is built as a layer over Amazon Web Services, Microsoft Azure, and Google cloud infrastructure. The business does not have to install specific hardware, and software instead it can use the support of in-house services. This makes it scalable and functions on a powerful architecture and data-sharing capabilities. Now since the platform separates the function of storage and computing, businesses can use and pay for both independently. Organizations with high storage demands but fewer CPU cycles and vice versa can thus tailor the platform to meet their needs accordingly. The data-sharing functionality also allows organizations to quickly share governed and secure data in real time. The Snowflake architecture comprises:
- Database storage layer that holds both structured and semi-structured data which is organized as per file size, structure, compression, metadata, and statistics.
- The compute layer, is a set of virtual warehouses that execute data processing tasks required for queries. Each warehouse or a cluster of them can access all the data in the storage layer without competing for computing resources.
- The cloud services layer uses ANSI SQL and coordinates the entire system eliminating the need for manual data warehouse management and tuning. It includes services such as authentication, infrastructure management, metadata management, query parsing, and access control.
Optimizing the performance of Snowflake to obtain benefits:
Before we begin, let us understand that pricing on Snowflake is mainly driven by credit consumption of storage and computing which in turn counts the number of tables in the environment, the SQL queries being run on those tables, and the sizes of the data warehouses.
1) To use the Multi-cluster warehouse or is it better to scale up /down:
We have discussed virtual warehouses, As queries are submitted to a warehouse, the warehouse allocates resources to each query and begins executing the queries. Note:
- If sufficient resources to execute all the queries submitted are unavailable, Snowflake queues the additional queries until the necessary resources become available.
- With multi-cluster warehouses, Snowflake allocates additional clusters to make a larger pool of computing resources available.
- Multi-cluster warehouses specifically help handle queuing and performance issues related to large numbers of concurrent users as well as queries.
- It also can automate this process if the number of users/queries tend to fluctuate.
Resizing a warehouse generally improves query performance, particularly for larger, more complex queries. If say a warehouse does not have enough resources to process concurrent queries, queuing can be reduced there. Businesses may use additional warehouses to handle workloads or multi-cluster warehouses as Snowflake supports resizing at any time even when queries are run.
The role of the cost governance tool: The storage section displays the number of credits used by the application connected to the account, and billing of snowflake features like snowpipe. The security section shows failed login users’ information and those who never logged in at all. The cost section displays credits consumed by the warehouse for specific features. Finally, the compute section gives the data of all jobs executed as per warehouse, an execution based on job users, warehouses used by different members, etc.
2) When to use Materialised View and when not to use it:
A materialized view is a pre-computed data set derived from a defined query (the SELECT in the view definition) and stored to be used later. Materialized views can speed up expensive aggregation, projection, and selection operations, especially those that run frequently and run-on large data sets. They are designed to improve query performance for workloads composed of common, repeated query patterns and usually incur additional costs for intermediate results. It is therefore essential to consider if costs are offset by the savings using MV by re-using these results frequently enough.
When to use:
- Query results contain a small number of rows and/or columns relative to the base table (the table on which the view is defined).
- Query results contain results that require significant processing, including:
- Analysis of semi-structured data.
- Aggregates that take a long time to calculate.
- The query is on an external table (i.e., data sets stored in files in an external stage), which might have a slower performance compared to querying native database tables.
- The view’s base table does not change frequently.
When not to use:
- A materialized view can query only a single table.
- Joins, including self-joins, are not supported.
- A materialized view cannot query another materialized view, A non-materialized view, or A UDTF (user-defined table function).
- A materialized view cannot include:
- UDFs (this limitation applies to all types of user-defined functions, including external functions)
- Window functions
- HAVING clauses
- ORDER BY clause
- LIMIT clause
- GROUP BY keys that are not within the SELECT list. All GROUP BY keys in a materialized view must be part of the SELECT list
- GROUP BY GROUPING SETS
- GROUP BY ROLLUP
- GROUP BY CUBE
- Nesting of subqueries within a materialized view
5) Many aggregate functions are not allowed in a materialized view definition. The ones that are supported are:
- APPROX_COUNT_DISTINCT (HLL)
- AVG (except when used in PIVOT)
- BITAND_AGG
- BITOR_AGG
- BITXOR_AGG
- COUNT
- MIN
- MAX
- STDDEV
- STDDEV_POP
- STDDEV_SAMP SUM
- VARIANCE (VARIANCE_SAMP, VAR_SAMP)
- VARIANCE_POP (VAR_POP)
Source: Snowflake.
3) Understanding the auto-resume/suspend strategy for a warehouse:
- Snowflake automatically suspends the warehouse if it is inactive for the specified period. This is done by default.
- Likewise; Snowflake also automatically resumes the warehouse when a query that requires a warehouse is submitted, and the warehouse becomes the current warehouse for that session. These properties can be used to simplify and automate the monitoring and usage of warehouses to match the workload.
- Auto-suspend ensures that warehouse credits are not wasted in the absence of incoming queries. Auto-suspend and auto-resume apply only to the entire warehouse and not to the individual clusters in the warehouse.
- Also note that Auto-resume is applicable only when the entire warehouse is suspended (i.e., when there are no clusters running).
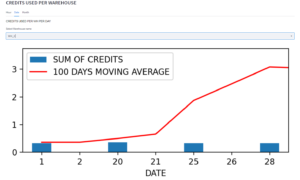
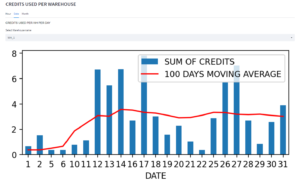
4) Detecting and optimizing long-running /expensive operations:
The cost governance tool helps track long and cost-intensive operations like longest-running tasks and subsequently, the credits consumed by warehouses, snow pipes, and other applications interacting with snowflake, storage, and data sharing to other snowflake accounts.
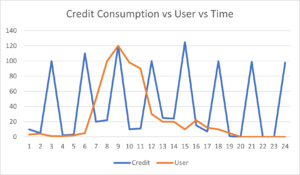
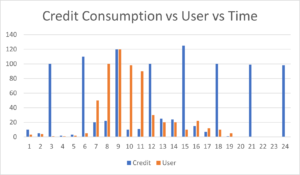
Based on the above reports, the application will allocate resources or distribute the workload accordingly for all features.
Multi-clustered XL warehouse consumes a significant amount of credits; understanding the pattern using the results from the consumption patterns businesses can separate the user load and batch operation load. When the consumption made by User loads is less, it can be routed to a smaller clustered warehouse. Batch Load can accordingly be routed to an XL standalone Warehouse, which can be resumed only during the Periodic Batch Load.

Tuning the Snowflake environment needs to be carried out with full focus data as bad quality output is expensive to the business. Without the right checks in place for usage and access to sensitive data, the costs involved are compromised as well as the benefits and features of Snowflake will remain underutilized.
Author List:
1. Ankit Kumar
2. Subhodip Pal